
微观案例#4:所有风险都是相关的——你在不经意间容忍了什么?
Background
在最近的 Micro-Case 我们展示了如何使用蒙特卡罗模拟来更有效地理解决策过程中的风险和暴露. 从那时起, 我们已经将这个概念应用到风险矩阵框架中,这已经被证明是有启发性的(因为它简化了复杂的风险结构,同时说明了潜在风险的真实水平)。.
风险矩阵建模
看到风险管理方法和框架是很常见的 (e.g. CIS RAM, COSO)依赖于分类测量(例如.g. 高、中、低) 对不利因素的风险和/或影响进行分类 事件. 的 吸引力在于简单的语言和数学可以帮助组织定义适当的 风险/影响级别,但是这种输入简单性的代价是 输出是复杂的,真实的风险概况被淹没在噪音中.
术语和微妙之处可能会改变,但本质上,a 风险概况通常由 x 风险项目分类 在 y 可能性分类和 z 影响 水平. 然而,独特组合的数量很快就会变得非常多 因此不可能清楚地评估. 对于x = 5 y = 3 z = 3,这里 1287个可能的结果集仅仅来自5个风险项目吗.
为了寻找一种高效直观的方法来计算 关注高风险/高影响并不罕见 组合,而不是用1,287或 更多的点. 然而,评估“更大”的风险并没有充分考虑 较低(但非常真实)的风险水平.
在这个微观案例中,我们展示了如何更好地理解 所有 固有风险可以通过一些方法和可视化来获得,我们目前正在部署这些方法和可视化来更好地表达风险.
超越传统风险框架
对于本文, 我们假设一个包含100个风险项的框架, 3个风险级别和3个影响级别(因此可能产生3520亿个结果集). 我们想展示一个“中等风险”的结果, 所以我们随机生成一个数据集大约有50%的概率 低 (等级1),40%的变化 媒介 (要求等级2级)并且有10%的几率 高 (3级)风险和影响. 我们的(人工)100项风险项目如下:
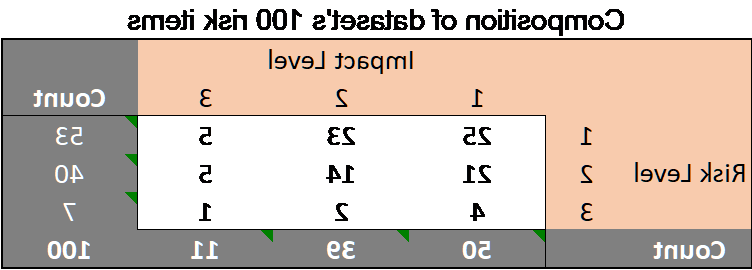
数据均值是1.54分风险和1分.61的影响-和热图(与抖动稍微分开相同的风险/影响点)如下所示,代表了一个相当普遍的, 中等健康概况,22项得分(风险*影响)为4或以上, 大于4的有8项.
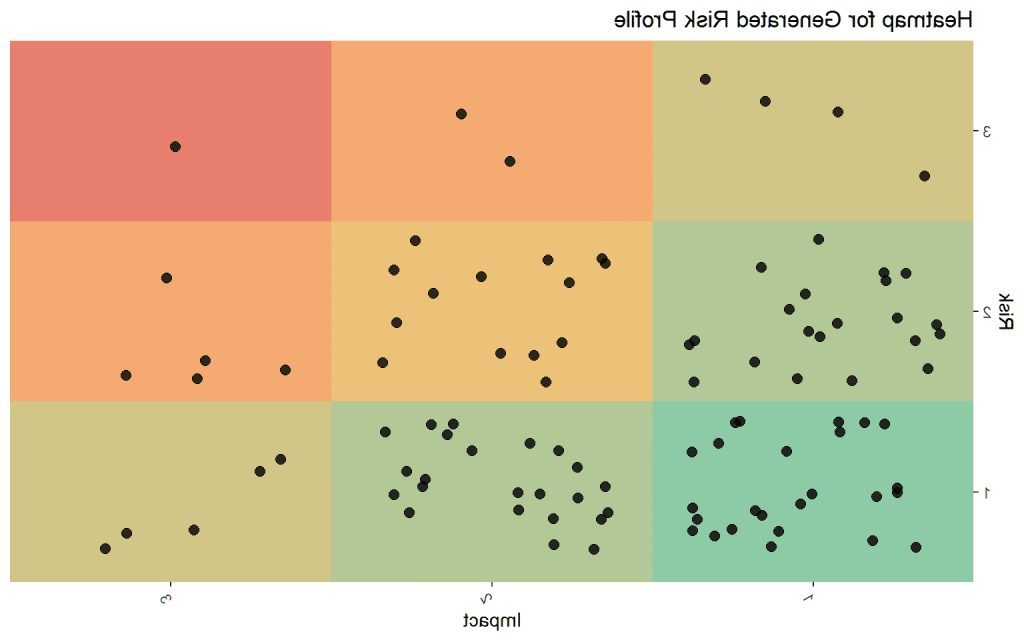
假设我们考虑 低 风险小于5%的几率 事件 发生在未来12个月, 媒介 是5-25%,和 高 有超过25%的吗. 现在,我们可以将概率分配给上述风险类别,并使用我们定义的风险/影响参数模拟可能的年份. 当然,这是假设,但考虑到风险/影响,这也是非常合理的. 在未来的12个月里,我们可能会看到一系列 事件 如下所示.
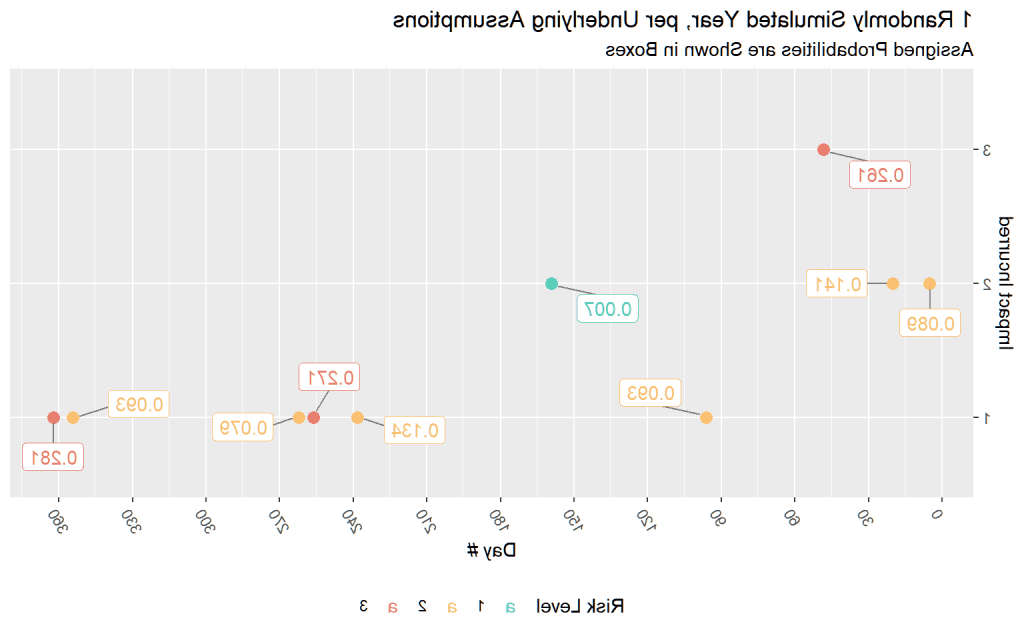
我们的模拟年,与我们定义的风险/影响参数经历了10 事件其中一次三级撞击发生在第47天左右. 方框显示了基于风险级别分配给特定风险项目的概率. 尽管大多数风险被认为是“低”(53/100), 我们确实看到第161天发生了2级影响事件,只有0级.发生几率7%. 因此,我们的模拟显示,根据我们的风险概况, 可能 看起来像. 显然,组织暴露在比可能接受的更有影响力的事件中,并且几乎肯定比我们在创建数据集时所期望的“中等”期望要多. 这是比100行风险矩阵更容易解释的风险表示.
事件概率分布
然而,这只是一个随机抽样的年份 数到10 事件 它本身就是主体 随机变化. 为了解决这个问题,我们进行了10,000次为期一年的模拟 得出一个有根据的结论.
下面我们通过计算模拟的次数创建了一个概率分布 事件 (包括零),每一年,在每个影响水平(横贯x轴). 然后我们计算所有的比例 事件 每个事件-count表示的概率,结果概率显示在y轴上.
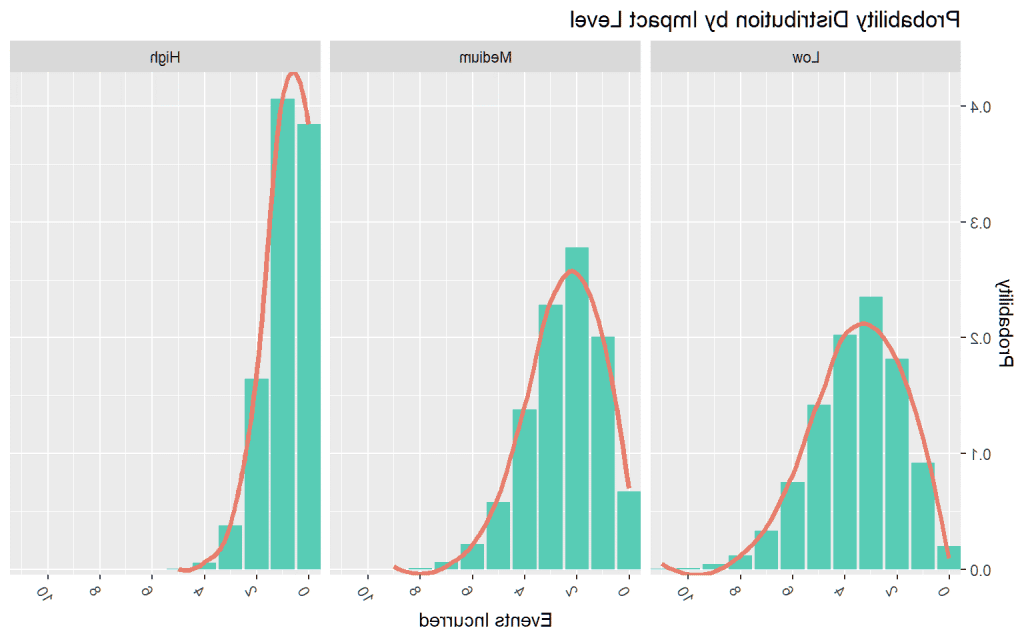
可以看出,根据我们的风险分类 黑客帝国,我们应该期待一些 事件 每个影响中最常见的事件 等级: 1级: 3, 2级: 2, 水平 3: 1.
更有启发性的是出现右尾年份的可能性 其中每个风险级别的事件数量可以为: 1级: 11, 水平 2: 9, 3级: 5.
因此,我们可以做出一些有根据的决定,什么是可接受的,什么是不可接受的. 我们所认为的“中等”企业风险水平看起来被大大低估了.
结论
这可能会让我们感到震惊,因为我们认为 媒介 风险水平实际上比预想的要高. 这是因为有大量的风险项目, 即使概率很小, 会导致非零水平的 事件. 用于评估风险矩阵固有的数十亿组合的传统度量往往忽略小(甚至中等)概率风险,而关注大概率风险,因为它们很容易识别和理解. 正是通过这种方式,企业往往承受了比他们认为的更大的风险. 通过生成事件的概率分布, 真正的风险可以更好地沟通和理解.
风险模型的消费者在面对风险矩阵和饼状/柱状图时,很难理解真正的风险敞口. 通过对每个分类风险级别应用概率分布, 然后根据风险概况模拟结果, 我们澄清了真正的风险暴露. 虽然模拟只能是真实潜在风险的近似值, 它让一个组织的真实暴露暴露无遗.
关于这个话题的问题? 联系保罗·牛顿,商业分析总监,邮箱:pnewton@4ugod.com.